cloud scheduler
- 2020 年 09 月 16 日
- cloud
keywords
- scheduler
- placement
- allocation
references
- dynamic placement for clustered web applications
- Entropy- a Consolidation Manager for Clusters
- A scalable application placement controller for enterprise data centers
决定每个应用启动多少实例和放在那台机器上
- A Scalable Application Placement Controller for Enterprise Data Centers
解决的问题:
30秒内,上千的机器和上千实例高质量的放置方案。 应用的动态扩缩容。
- 满足最大的应用放置需求
- 最少启动、停止应用
- 物理机的均衡度
The placement problem is NP hard.
- approximation algorithms 近似算法 [6] A. Karve, T. Kimbrel, G. Pacifici, M. Spreitzer, M. Steinder, M. Sviridenko, and A. Tantawi. Dynamic Application Placement for Clustered Web Applications. In the International World Wide Web Conference (WWW), May 2006. [8] T. Kimbrel, M. Steinder, M. Sviridenko, and A. N. Tantawi. Dynamic Application Placement Under Service and Memory Constraints. In International Workshop on Efficient and Experimental Algorithms, 2005.
Objective Virtual Machine Placement in Virtualized Data Center Environments
- In this paper, a two-level control system is proposed to manage the mappings of workloads to VMs and VMs to physical resources.
- a multi-objective optimization problem
- minimizing total resource wastage 资源最小浪费
- power consumption 电量消耗少
- thermal dissipation costs 热能消耗(需要冷却系统来保证机房在安全温度)
- 算法
- An improved genetic algorithm (改进的遗传算法) with fuzzy multi-objective evaluation(模糊的多目标评估?)
- 目的是:
- 高效的搜索大的解空间
- 便于兼备优化的冲突目标
- 和4个知名的装箱算法(bin-packing)/2个单目标优化方法的比较,从如下几个方面比较
- power-consumption(电力消耗)
- thermal-dissipation models
- good performance
- scalability
- robustness
- 优势
- 当其他的算法无法做到时,该算法能寻找到优化冲突目标存在的均衡的解
- 使用场景
- the problem of initial VM placement/VM的初始调度(where a number of requests for VMs are to be placed to the available physical resources. )
- 机房刚开始运营、重置、空置后重新启用。有一批VM需求,批量来放置。
- 一次性放置
- 尝试搜索最优解
- 优化目标
- 高效实用多维度资源(CPU/Memory/disk…)
- 避免热点(hot spots)
- 减少能量(电能)消耗
- [不是该论文的目标]在可接受的时间里,找到一个近视最优解(Intelligent search)
- 目标:搜索全局最优解,模糊逻辑(fuzzy-logic)的评估方法来综合不同的优化目标。??
- 其他场景
- Dynamic VM placement,动态放置(迁移)
章节详细记录
- [2]background
- [3]framework
- [4]描述问题和提议的解法
- [5]实验结果、分析算法的性能
- [6]相关工作
- [7]总结论文
[2] background
- combinatorial optimization
-
multi-objective optimization and fuzzy logic
- combinatorial optimization(组合优化) and genetic algorithms(遗传算法)
- NP-hard:scheduling/packing/placement
- Heuristic techniques(启发式算法/方法/技术),求解近似解 solving optimization problems in an approximate way / global optimal solutions
- genetic algorithms(遗传算法),能很好的解决 combinatorial problem(组合问题)
[4]
- Grouping Genetic Algorithm
- ranking-crossover, 不直接使用随机的crossover
虚拟化的收益
降低成本,更少的机器、更少的电力消耗,更少的冷却系统,物理空间等
### 启发法(Heuristic techniques)
- 不保证最优、完美、最合理
- 足够快速、短期目标、近似解法
- 搜索最优解释不可能或者不可实现(NP hard),启发法可以用来加速搜索满意的解
NP hard
很多组合问题(combinatorial problems)被分类为NP-hard
- 调度(scheduling)
- 装箱(bin packing)
- 放置(placement) 遗传算法(genetic algorithms)常被用来解决组合问题
###
- approximate global optimum 近似全局最优
- precise local optimum 精确的局部最优
《A Multi-objective Approach to Virtual Machine Management in Datacenters》
- dynamic VM placement(动态放置,二次迁移)
- ThermalEmergency
- Resource Contention
- Low Energy Efficiency
- Condition Detection (trigger a VM-migration)
- 怎么检测准确,避免无效的迁移
- Virtual Machine Selection (选择要迁移的VM)
- Thermal Emergency
- Resource Contention
- Low Energy Efficiency
- Host Selection(迁移的目标机器)
- Temperature
- cooling cost
- Power
- Performance
- 其他相关工作
- VMware’s Distributed Resource Scheduler (DRS)
- CPU & Memory
- 不考虑温度、电力消耗
- VMware Distributed Power Management (DPM)
- 物理机使用的数量
- 关掉不使用的物理机
- 不考虑: 资源竞争、热效应、VM迁移的影响
- VMware’s Distributed Resource Scheduler (DRS)
《Dynamic Placement for Clustered Web Applications》
-
use clustering technology to provide scalability, high availability and load balancing.
- Placement Algorithm
- Residual placement
- Incremental placement
- Rebalancing placement
- 评估方法 Evaluation criterion
- Gini index
《A scalable application placement controller for enterprise data centers》
- within 30 seconds
- solutions for hard placement problems with thousands of machines and thou- sands of applications
- to maximize the total satisfied application demand
- to minimize the number of application starts and stops
- to balance the load across machines.
- 和 state-of-the-art algorithms 对比。
- 提速 134 倍
- 减少97%的开、停机
- 满意度提升25%
- request router 路由
- admission control 访问控制
- flow control 流量控制
- load balancing 负载均衡
- 抽象为:多项限制的多背包问题。多个优化目标
- 满足最大量的需求
- 尽可能少的开、停机
- 均衡负载
- This problem is a variant of the Class Constrained Multiple- Knapsack problem
-
动态的启动、停止应用
- bin packing 装箱问题
-
multiple knapsack 多重选择背包问题
- 流程
- 算出一个放置方案
- 执行器,执行停止、启动任务
- 定时循环
- 假设
- 应用没有请求量,也会消耗对应的内存
- 内存的消耗,memory consumption is often related to prior application usage rather than its current load due to data caching and delayed garbage collection.
- 简化
- 只考虑CPU和内存,当然也可以处理其他的资源
- placement algorithm 具体的放置算法
- 定时循环优化放置问题
- 所有的应用都满足,那么就结束
- 有不满足的,就停止其他不需要的,然后启动需要新需求的
- 实例运行状态分类
- idle 空闲
- underutilized 不完全使用
- fully utilized 完全使用
- Key Ideas
- 同一时间只考虑单独的机器,降低计算时间
- 只考虑单独机器,放置可能不合理,所以:执行多轮,前面一轮停掉的实例资源,就可以分配给后面一轮的需求
- 考虑CPU/Memory的比例
- 减少变更(如:pinned实例,就不会变动)
- Proof 证明
- contradiction 使用反正
- The placement-changing
-
increase the total satisfied application demand
- 第一尽可能多的满足实例的放置需求
- 满足的数量一样的话,那就是尽可能少变动实例(不要停止、开启)
-
- 算法评估
- performance
- execution time
- the number of placement changes
- the demand satisfaction
- 可以支持上千的机器和实例(应用)
- 实例(应用)的变化也很少(相比其他的算法)
- 三方面的提高
- 执行时间 (the strategy that does place- ment changes to machines one by one in an isolated fashion.)
- 应用的需求满意度 (its load-shifting heuristics and the strategy that first does placement changes to the ma- chines with a high CPU-memory ratio. )
- 应用的变化数量 (Two heuristics in the new algorithm help reduce placement changes:application instance pinning and machine isola- tion.)
- performance
《Large-scale cluster management at Google with Borg》
- long-running services that should “never” go down(e.g., Gmail, Google Docs)
-
for internal infrastructure services (e.g., BigTable)
- 很多系统都是建在Borg之上的
- MapReduce system
- FlumeJava
- Millwheel
- Pregel
- GFS/CFS, BigTable
- Megastore
- 分为两类系统
- production(prod)
- non-production(non-prod)
- 中等规模
- 10k machines
-
限制/约束 分强、弱(hard/soft)
- 相关工作
- Facebook’s Tupperware
- Twitter’s Aurora
- Microsoft’s Autopilot
- Microsoft’s Apollo
《Borg, Omega, and Kubernetes》
Borg 和 Kubernetes 介绍比较多。 Omega相对比较少
- container 管理系统
- Borg-> Omega-> Kubernetes
- Borg
- long-running services
- batch jobs
- 经验教训
- Don’t make the container system manage port numbers
- Don’t just number containers: give them labels
- Be careful with ownership
- Don’t expose raw state
《An Overview of Openstack Architecture》
-
modular & highly configurable architecture
- Computing
- Nova:
- Glance: Image Service
- Networking
- Neutron: networking
- DHCP
- IP’s
- VLAN’s
- Neutron: networking
- Storing
- Swift:Openstack Object Storage
- Cinder:Openstack Block Storage & Cinder Volumes
- Shared services
*Keystone: authentication
- Horizon:dashboard
- Ceilometer:configurable
- Advanced Message Queue Protocol:messaging
《Dynamic Resource Allocation with Management Objectives— Implementation for an OpenStack Cloud》
- a set of controllers that allocate resources to applications
- cooperate to achieve an activated management objective
- Management objectives define the strategies according to which resources are allocated to applications.
- balanced load objective
- minimizing power consumption
- fair resource allocation
- 【】want to satisfy several management objectives at the same time
- an optimization problem.
- colocation constraint
- anti-colocation constraint
-
descheduling & coscheduling
- Related work
- VSphere’s resource management system is the Distributed Resource Scheduler (DRS)
-
Microsoft Sys- tems Center (MSC)
- OpenStack
- Nova 计算
- API(http)
- compute(Rpc)
- conductor(Rpc)
- Nova-scheduler(Rpc)
- 依赖placement
- 水平扩展能力和方案 Both schedulers are able to scale horizontally, so for high-availability purposes, or for very large or high-schedule-frequency installations, you should consider running multiple instances of each scheduler. The schedulers all listen to the shared message queue, so no special load balancing is required.
- Queue
- placement
- migration
-
Cinder Scheduler
- Keystone: Authentication service.
- Glance: mirroring service.
- Nova: Computing services.
- Cinder: Block storage service.
- Neutorn: Network service.
- Swift: Object storage service.
- Nova 计算
-
无状态(stateless) & 扩展(scaling) Nova
-
read nova source code https://www.programmersought.com/article/57984562657/
- Distributed Computing
- In parallel computing, all processors may have access to a shared memory to exchange information between processors.
- In distributed computing, each processor has its own private memory (distributed memory). Information is exchanged by passing messages between the processors.
- CFS-Completely Fair Scheduler
云计算
- 2020 年 08 月 27 日
- cloud
- enterprise cloud (single organization)
- public cloud (man organizations)
History
- “cloud computing” appeared as eayly as 1996.
- 2006 AWS的EC2(Elastic Compute Cloud)
- 1960s, time-sharing(时分)
Types
IaaS (Infrastructure as a Service)
PaaS (Platform as a Service)
SaaS (Software as a Service)
Cloud Native
- Containerization
- CI/CD
- Orchestration & Application definition
- Observability & Analysis
- Service proxy, Discovery & Mesh
- Networking, Policy & Security
- Distributed database & Storage
- Streaming & Messaging
- Container Registry & Runtime
- Software distribution
The Twelve-Factor Application
- 弹性伸缩
- 集群中Node的伸缩
- pod的伸缩
-
可观测性
- 消息队列
- request/response messaging
- request/reply
- command
- Event bus
Cloud-native data patterns
- CAP
- Consistency
- Availability
-
Partition Tolerance
- Relational database systems: CA(Consistency & Availability)
-
NoSQL databases: AP(abailability * Partition Tolerance)
- Cloud-native resiliency
- Monitoring and health
- logging/monitoring/alerts
- Logging with Elastic Stack
-
Monitoring in Azure Kubernetes Services(Prometheus)
- Cloud-native identity/security
- DevOps
2015-CHASE- Component High Availability-Aware Scheduler in Cloud Computing Environment
2013-Apache Hadoop YARN- Yet Another Resource Negotiator
- Apache Hadoop
- RM(Resource Manager)
- tracks resource usage
- node liveness
- enforces allocation invariant
- arbitrate contention
- NM(Node manager)
-
AM(Application Manager)
-
YARN framework/application writers
- YARN in the real-world
- YARN at Yahoo!
-
MapReduce
- availability-aware scheduling technique
Fuxi ParSync
- distributed cluster scheduler
- sharding & multiple schedulers
- Workload statistics
- 4 millon jobs & 4 billon tasks
- 87% of tasks are completed in less than 10 seconds
- Partitioned Synchronization
Omega: flexible, scalable schedulers for large compute clusters
- Shared state
-
optimistic concurrency
- 3.1 Monolithic schedulers
- 3.2 Statically partitioned schedulers
- 3.3 Two-level scheduling(Mesos) YARN
- 3.4 Shared state(Omega)
- fuxi is similar to Omega?
- how to syn state
- kubernetes’s scheduler
- 异构资源 GPU
Benefits
- 灵活 Flexible
- 弹性 Scalable
- 节约成本 Cost effective
CDN
- Akamai
- google CDN
- microsoft azure CDN
- AWS CDN
Compute
- CPU
- GPU
- FPGA
- TPU
- ASIC
OpenStack
- nova(Compute)
- scheduler
- Scheduler Evolution
- Filter Scheduler
- filtering:一个过滤器集合
- weighting:排序
- nova-scheduler是nova(compute)的一部分
- nova使用scheduler来决定怎么分发(dispatch)资源的请求。VM在那一台物理机上运行。
- 过滤器(filters)
- 是否在指定的AZ、CPU/Memory/disk/architecture/hypervisor/vm mode/亲和性(Affinity)/反亲和性(AntiAffinity)
- placement: 库存,提供API
- resource provider inventories and usages. tracks the inventory and usage of each provider
- compute node
- shared storage pool
- IP allocation pool
- 有标准的DISK/MEMORY/VCPU,也可以自定义分类(custom resource classes )
- nova-compute(注册、删除、管理) 和 nova-scheduler(调度)会和placement交互
- scheduler提供调度的服务器和备选服务器 link
- 组件(componets)关系
- nova-api —-RPC—> super conductor
- 还有cell conductors/cell-local conductors
- super conductor 发送请求给 scheduler(不是cell conductors)
- conductor 调度完成后,再发送生产请求到 nova-compute
- 生产包含:网络port、磁盘、虚拟机 Walkthrough of a typical Nova boot request
组件关系
- Horizon(Dashboard) / OpenAPI 对外界面
- keystone 认证
- nova 计算API、实例管理API (计算)
- swift 对象存储 (存储-对象)
- cinder 块存储 (存储-块)
- glance 镜像服务 (镜像)
- neutron 网络 (网络)
- cells 可以部署更大的集群,每个cell是个独立的一组数据(相当于一个分片)。
It supports very large deployments.
将集群中的机器分组,分组就是cell,
NP-hard
- task scheduling
- packing
- placement
Heuristic techniques 启发式常用于一种近似方式解决优化问题。
- is not guaranteed to be optimal、perfect、rational
- immediate、short-term goal、approximation
- derived from previous experiences with similar problems
- readily accessible 易接近的
- though loosely applicable 尽管松散的适用
computer CPU architecture
- Branch predictor(分支预测) : 尝试猜测程序执行的逻辑,主要目的还是提速,让cpu的指令流水线(instruction pipeline)更快的执行
- Static branch prediction。编译时就确定。
- Dynamic branch prediction。运行时确定。
- Random branch prediction
- Next line prediction
- One-level branch prediction
process schedule in OS
- Long Term or job scheduler
- Short term or CPU scheduler
- Medium-term scheduler
cpu schedule in OS
- Arrival Time: Time at which the process arrives in the ready queue.
- Completion Time: Time at which process completes its execution.
- Burst Time: Time required by a process for CPU execution.
- Turn Around Time: Time Difference between completion time and arrival time.
- Turn Around Time = Completion Time – Arrival Time
- Waiting Time(W.T): Time Difference between turn around time and burst time.
- Waiting Time = Turn Around Time – Burst Time
Objectives of Process Scheduling Algorithm
- Max CPU utilization [Keep CPU as busy as possible]
- Fair allocation of CPU.
- Max throughput [Number of processes that complete their execution per time unit]
- Min turn around time [Time taken by a process to finish execution]
- Min waiting time [Time a process waits in ready queue]
- Min response time [Time when a process produces first response]
Scheduling Algorithms
- First Come First Serve (FCFS)
- Shortest Job First (SJF)
- Longest Job First (LJF)
- Shortest Remaining Time First (SRTF)
- Longest Remaining Time First (LRTF)
- Round Robin Scheduling [the time-sharing system]
- Priority Based scheduling (Non-Preemptive)
- Highest Response Ratio Next (HRRN)
- Multilevel Queue Scheduling
-
Multi level Feedback Queue Scheduling
- kube-scheduler
- List-Watch
- scheduling
- binding
Guidelines to follow when creating architectural diagrams
- Keep structural and semantical consistency across diagrams/保持各图的结构和语义的一致性
- Prevent diagrams fragmentation/防止图示碎片化
- Keep traceability across diagrams/保持跨图表的可追溯性
-
Add legends next to architectural diagrams/在建筑图旁添加图例
- Application architecture diagram
- Integration architecture diagram
- Deployment architecture diagram
- DevOps architecture diagram
- Data architecture diagram
- shaps lines arrow
- diagram legend
a picture is worth a thousand words
- sh
- bash
- zsh
- ksh
vlan & vxlan
Function compute
- aws lambda
- GCP Function
-
Azure Function
- trigger
Containers at AWS
Gateway
- ingress/egress
- Higress
mesh
- istio
- envoy
nginx
- upstream
- proxy pass
- http/3 QUIC
AWS
Fargate
Amazon Elastic Kubernetes Service (EKS)
Amazon EventBridge
- receive, filter, transform, route, and deliver events
- 接受,过滤,转换,路由,投递
triggers
- http
- MQ
software life circle
- life circle
-
ci/cd
-
dns
- lvs
- keeplived
service mesh
包粒度重传 3/4/7 gateway api gateway lvs
- nginx:SSL/HTTP2/gRPC
-
prototype
- cache
- lru
CPU scheduler
- CFS
- period & quota
- cpu.shares
- affinity
- isolation
References
- [1] Dynamic Resource Allocation by Using Elastic Compute Cloud Service
- [2] Cloud Computing Resource Scheduling and a Survey of Its Evolutionary Approaches
- [3] architectural-diagrams
- [4] Design for scalability
- [5] Predictive Scaling for EC2, Powered by Machine Learning
- [6]aws lambda
- [7] [GCP Funtions]
- [8] [how exxx function works]
- [9] higress
- [10] service mesh
- [11] Implementing Data Center Overlay Protocols
- [12] vlan互访
- [13] http2
- [14] grpc-nginx
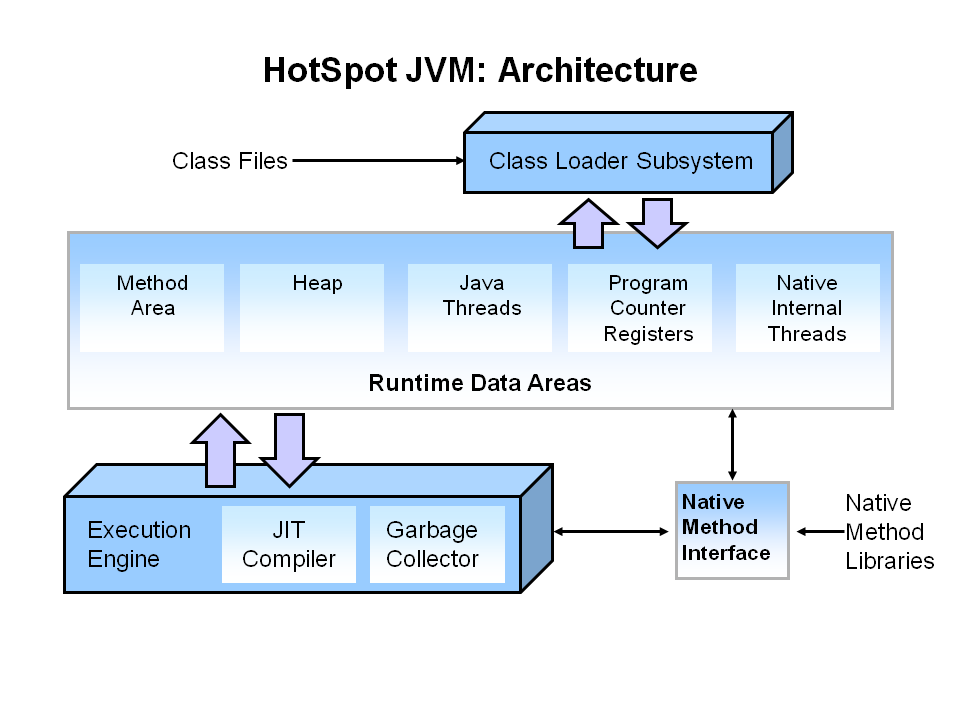
java gc
- 2020 年 08 月 14 日
- java
gc算法
- 引用计数法
循环引用的,孤岛问题
- 可达性分析
- 标记-清除
分为2个阶段
- 标记
清除 不足
- 标记、清除的效率问题
- 空间碎片
- 标记-复制
需要双份大小的内存大小
- 高效
- 内存空间大
- 新生代常用
- 标记-整理
分2个阶段,标记和整理
- 整理直接将对象移动到一起
常用垃圾收集器
- Serial
单线程
- ParNew
新生代(young generation),多线程(parallel threads)
- Parallel Scavenge
新生代,多线程,主要考虑吞吐量(throughput collector)。用户线程时间/总时间
- Serial Old
- Parallel Old(Parallel Scavenge Old)
- 多数jdk8的默认GC,也有将默认设置为CMS的,所以最好明确设置
- the parallel garbage collector for full GCs
-XX:+UseParallelGC
当使用ParallelGC时,可以使用-XX:+UseNUMA
- 设置参数
-XX:MaxGCPauseMillis=time Sets a target for the maximum GC pause time (in milliseconds).JVM会努力
达到,但是不一定能达到
- CMS
CMS(老年代)+ParNew(新生代),java9不建议使用
-XX:+UseConcMarkSweepGC -XX:+UseParNewGC
- G1
建议堆大小>6GB时使用
- Region。没有明确的新生代、老年代,逻辑的区分
- 初始标记 Initial Marking
- 并发标记 Concurrent Marking
- 最终标记 Final Marking
- 筛选回收 Live Data Counting and Evacuation
javaagent
- JDK动态代理
- ASM
- Javassist
- Byte Buddy
- Cglib
- AspectJ
links
服务高可用,限流、降级
- 2020 年 08 月 10 日
- service
使用场景
随着服务架构的演进,现在一项服务基本都是分布式的架构,多个微服务可能彼此调用。 限流、服务降级、服务熔断主要使用词场景和目的是什么?
<pre>
+----------------+
| |
| Service A | -----+
| | |
+----------------+ | +----------------+
|---->| |
+----------------+ | Service D |
| | |---->| |
| Service B | -----+ +----------------+
| |
+----------------+
</pre>
- Service D 保护自己,限流
- Service A/B 因为D的问题,要服务降级、熔断
Hystrix
- latency tolerance
- fault tolerance
流程图
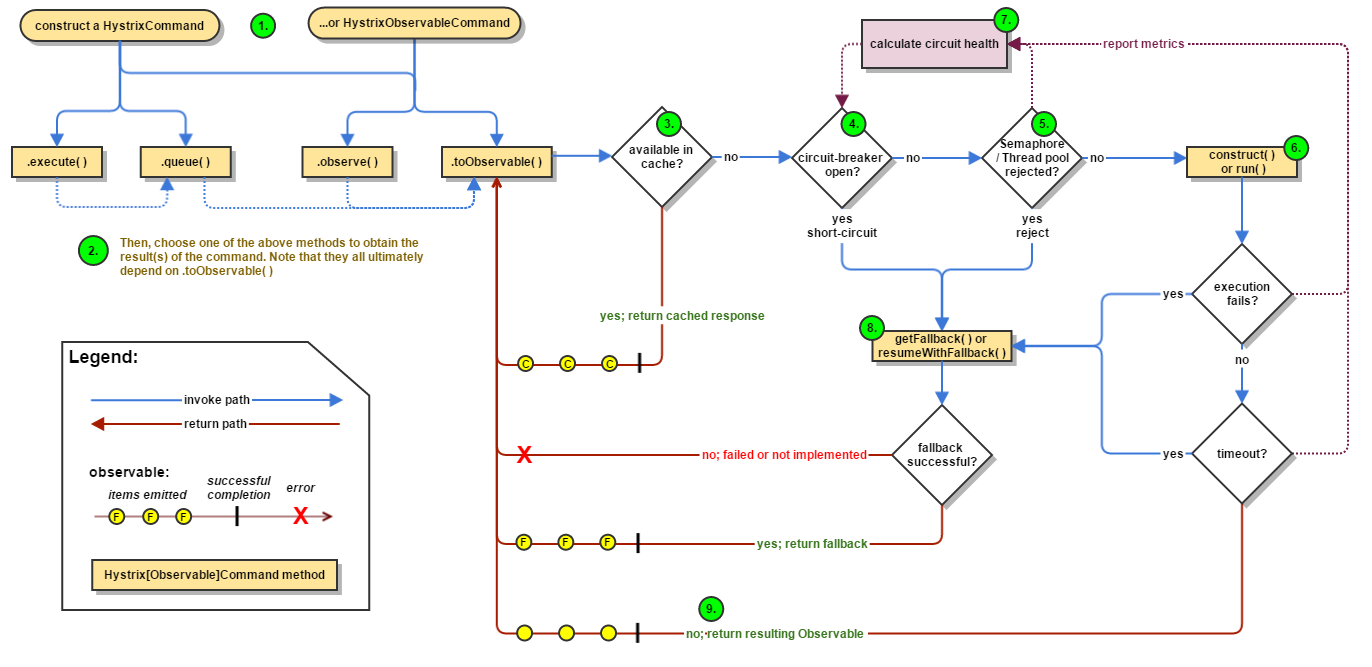
links
机器学习基础
- 2020 年 07 月 26 日
- ML
AI算法
AI > 机器学习 > 深度学习
- supervised
- Unsupervised
- Reinforcement learning
深度学习
- 胶囊神经网络
- Attention 机制
-
深度学习 - Deep learning DL -
长短期记忆网络 - Long short-term memory LSTM -
生成对抗网络 - Generative Adversarial Networks GAN -
循环神经网络 - Recurrent Neural Network RNN - 卷积神经网络 - CNN
-
强化学习-Reinforcement learning RL - RNN->LSTM
- Encoder-Decoder Seq2Seq
-
Transformer BERT Bidirectional Encoder Representation from Transformers - GPT (OpenAI)
机器学习
- 线性回归 - linear regression
- 逻辑回归 - Logistic regression
-
朴素贝叶斯 - Naive Bayes classifier NBC - Adaboost 算法
- 随机森林 - Random forest
-
支持向量机 - Support Vector Machine SVM - 决策树 - Decision tree
- K均值聚类(k-means clustering)
- 集成学习(Ensemble Learning)
基础科普
- 深度学习、神经网络、机器学习、人工智能的关系
- 机器学习是AI的一个分支
- 深度学习是机器学习的一个重要分支
- 深度学习的概念源于人工神经网络的研究,但是并不完全等于传统神经网络。(是传统神经网络的升级,约等于神经网络)
- 神经网络是一个网络结构,深度学习就是对这个网络结构进行调整()
传统机器学习: 数据预处理 --> 特征提取 --> 选择分类器 深度学习 : 数据预处理 --> 设计模型 --> 训练
- 4种典型的深度学习算法
- CNN 卷积神经网络,最擅长图片处理
- CNN 的基本原理: 卷积层 – 主要作用是保留图片的特征(提取图像中的局部特征) 池化层 – 主要作用是把数据降维,可以有效的避免过拟合(用来大幅降低参数量级(降维)) 全连接层 – 根据不同任务输出我们想要的结果
- 运用场景 图像分类、检索:图像搜索 目标定位检测:自动驾驶、安防、医疗 目标分割:美图、视频后期加工、图像生成 人脸识别:安防、金融、生活 骨骼识别:安防、电影、图像视频生成、游戏
- RNN 循环神经网络
- 特点 卷积神经网络 – CNN 和普通的算法大部分都是输入和输出的一一对应,也就是一个输入得到一个输出。不同的输入之间是没有联系的。 RNN 跟传统神经网络最大的区别在于每次都会将前一次的输出结果,带到下一次的隐藏层中,一起训练。 RNN 有短期记忆问题,无法处理很长的输入序列 训练 RNN 需要投入极大的成本 由于 RNN 的短期记忆问题,后来又出现了基于 RNN 的优化算法
- 优化 LSTM 和 GRU RNN 是一种死板的逻辑,越晚的输入影响越大,越早的输入影响越小,且无法改变这个逻辑。 LSTM 做的最大的改变就是打破了这个死板的逻辑,而改用了一套灵活了逻辑——只保留重要的信息。 GRU 主要是在 LSTM 的模型上做了一些简化和调整,在训练数据集比较大的情况下可以节省很多时间
- 使用场景 文本生成:填空题,给出前后文,然后预测空格中的词是什么。 机器翻译:翻译工作也是典型的序列问题,词的顺序直接影响了翻译的结果。 语音识别:根据输入音频判断对应的文字是什么。 生成图像描述:类似看图说话,给一张图,能够描述出图片中的内容。这个往往是 RNN 和 CNN 的结合。 视频标记:他将视频分解为图片,然后用图像描述来描述图片内容。
- GANs 生成对抗网络
- RL 深度强化学习
标量 scalar
标量只有大小概念,没有方向的概念。
- CNN 卷积神经网络,最擅长图片处理
点——标量(scalar) 线——向量(vector) 大小(箭头的长度)和方向(箭头的方向) 面——矩阵(matrix) 体——张量(tensor)
分类模型评估指标
- T=机器判断对不对 T=对,F=不对
- P=机器判断是不是 P=是,N=不是
- TP=对/是 判断是对的,是=1
- FP=不对/是 判断是不对的,所以本身应该是0
- FN=不对/不是 判断是不对的,所以本身应该是1
- TN=对/不是 判断是对的,本身应该是0
- 准确率 Accuracy = (TP + TN)/(TP+TN+FP+FN) 判断的对不对(是和不是都判断对了)
- 精准率 Precision = TP/(TP+FP) 判断对的比例(机器认为是正例,但是有不对的)
- 召回率 Recall = TP/(TP+FN) 判断对的,占本身是的比例,还有一部分也是,但是判断错F了成N
- F1 F1= (2PrecisionRecall)/(Precision+Recall)
- ROC曲线 (Receiver Operating Characteristic)
- AUC曲线
线性回归
无监督学习
| ---> 回归 ---> 线性回归
机器学习--> 监督学习
| ---> 分类 ---> 逻辑回归(二分类)
强化学习
回归的目的是:预测
决策树
分类。 根节点、内部节点、叶节点
- 特征选择
- 决策树生成
-
决策树剪枝,主要目的是对抗「过拟合」
- 主要算法
- ID3 算法 : 利用信息增益来选择特征的
- C4.5 算法: ID3的改进版,不是直接使用信息增益,而是引入“信息增益比”指标作为特征的选择依据。
- CART(Classification and Regression Tree)即可以用于分类,也可以用于回归问题。CART 算法使用了基尼系数取代了信息熵模型。
Encoder-Decoder 和 Seq2Seq
机器学习
SVM 支持向量机 – Support Vector Machine | SVM
- 超平面
- 支持向量
逻辑回归
- 主要解决二分类问题,用来表示某件事情发生的可能性。
逻辑回归 & 线性回归 对比
- 线性回归: 解决回归问题;连续的变量;符合线性关系; 直观表达变量关系
- 逻辑回归: 解决分类问题;离散的变量;可以不符合线性关系;无法直观表达变量关系
朴素贝叶斯 – Naive Bayes classifier | NBC
深度学习
前馈神经网络(Feedforward neural network)
- 一种最简单的神经网络,各神经元分层排列。每个神经元只与前一层的神经元相连。
- 接收前一层的输出,并输出给下一层,各层间没有反馈。
强化学习
强化学习是机器学习的一种学习方式,它跟监督学习、无监督学习是对应的. 强化学习并不是某一种特定的算法,而是一类算法的统称。
强化学习的主流算法
- 免模型学习(Model-Free)
- 有模型学习(Model-Based)
自然语言处理
- 词性标注 - Part of speech
- Word2vec
-
命名实体识别 - Named-entity recognition NER -
自然语言理解 - NLU NLI
计算机视觉
- CNN
语音交互
- LSTM
BM25
- 单词和目标文档的相关性 WD
- 单词和查询关键词的相关性 WQ
- 单词的权重部分 WT
WDWQWT
BM25变种
- BM25F F=field
- BM25 + PageRank
语言模型
核心思想:希望用概率模型(Probabilistic Model)来描述查询关键字和目标文档之间的关系。 最简单的类型:
- 查询关键字似然检索模型(Query Likelihood Retrieval Model)。简单来说,一个语言模型就是一个针对词汇表的概率分布。